

 English
English Español
Español

If you’ve ever needed to quickly translate a text online, you’ve likely tried Google Translate or another free alternative. For non-professionals, these tools can be lifesavers to get at least the basic idea of a text in another language. The results range from acceptable to ludicrous, but the process feels like magic. So how do these machines actually work?
Google Translate initially used statistical machine translation, like many machine translation (MT) products at the time. Starting in 2016, all of these MT services began to shift to neural machine translation, which is now the most common technology for consumers. A new neural translator launched in 2017, DeepL, has also grown in popularity.
But how exactly does machine translation work? We all know it required more than just a dictionary and some rules of grammar, so what do these machines do? Let’s take a look:
Parallel corpora
Most MT uses parallel corpora, which are databases of bilingual texts from a variety of sources. Either a human team or artificial intelligence select these texts and enter them into the corpus, a huge library of example translations that MT can draw from. The bilingual texts used in an MT corpus are typically scoured from internet pages, meaning that they likely utilize work done by human translators. It’s hard to verify the accuracy of these translations, or even know how they have been selected, but we know they are the result of a lot of human labor.
The corpus used by DeepL is called Linguee, and the company claims that Linguee improves upon traditional corpora by using specialized Internet bots called “crawlers,” which automatically source translations on the internet. The crawlers also assess the quality of the translations they collect, although the company, based in Germany, doesn’t say how.
When you use Google to search for a translation, typing a phrase with “in Spanish” or “in French,” etc., Linguee often appears at the top of the results. This search popularity in Google allowed Linguee to generate revenue from ads on their website before the launch of DeepL.

Statistical machine translation (SMT)
Google Translate, likely the most famous MT service, previously used statistical machine translation technology. Most of its competitors, such as Microsoft Translator (previously Bing Translator) and Yandex Translate, from a Russian company, used similar technology.
When you enter a source text, SMT uses statistics to judge the most likely translation based on the corpus. It does not know the rules of grammar or common usage, only the most mathematically probable translation based on example translations in the corpus.
SMT has many problems with grammar, word order, and the limits of the corpus: it can only translate a phrase if it exists in the corpus. Even if it does exist, if the machine translator does not find many results for a word in the corpus, it may fill in another that it judges more statistically probable. Furthermore, SMT tends to be based on phrases, limiting its capabilities for longer sentences or texts. To learn more about SMT, see the link below:
Neural machine translation (NMT)
Today, Google Translate and its competitors, including DeepL, use neural machine translation. This method also uses parallel corpora, but abandons statistical models for artificial neural networks. These networks are computing systems designed to imitate human brains. They are capable of recognizing patterns in the corpus and producing results based on these patterns. This process is also known as deep learning, hence the name of DeepL.
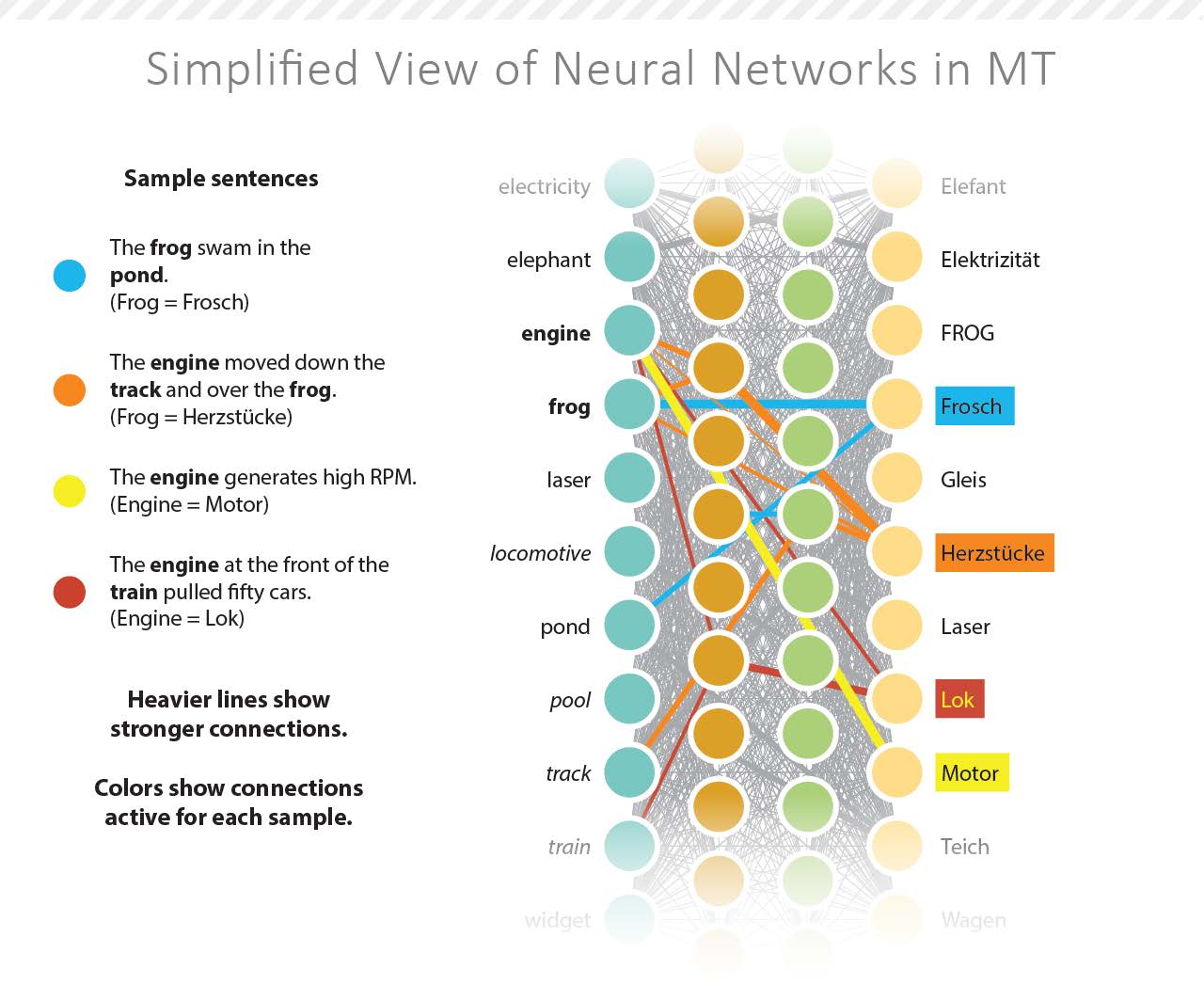
Deep learning can be supervised, unsupervised, or semi-supervised by human programmers. DeepL has not shared much information about how their supposed improvements work. To learn more about machine learning as it relates to translation, see the link below:
Neural machine translations are more accurate than SMT and appear to produce more “fluent” translations, although this apparent fluidity can mask deeper accuracy or readability issues. See the example below:
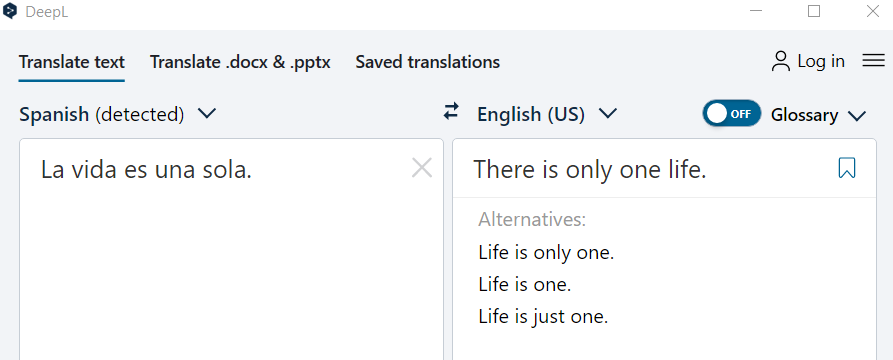
This common idiom in Spanish is easily translated to “you only live once.” DeepL’s translation has no grammatical errors, but loses meaning for an English-speaking public. Since the majority of MT users are not highly bilingual, they may not detect this error.
This technology has advanced greatly, but do not be fooled: NMT does not produce perfectly accurate or fluent translations. For important technical documents or communications with clients and customers, it may not be the right choice for you. At Southern Cone Translations, we are happy to explore all the options to best meet your needs. Reach out to us if you have questions.
Is machine translation the right choice for your image? See our last blog to learn more:

