

 Español
Español English
English

Si alguna vez ha tenido la necesidad de traducir algo en línea rápidamente, es muy probable que haya recurrido al Traductor de Google u otra alternativa gratuita. Para las personas que no ejercen como traductor profesional, estas herramientas le pueden salvar la vida en un momento de apuro o ansiedad, para poder al menos hacerse una idea básica de qué se trata el texto en otro idioma. Los resultados varían entre ser aceptables y totalmente disparatados, pero el proceso parece ser mágico. Entonces, ¿cómo funcionan estas máquinas realmente?
Cuando se lanzó el Traductor de Google, usaba lo que se denomina la traducción automática estadística, igual que muchos productos de la traducción automática (MT por sus siglas en inglés) de ese entonces. A partir del 2016, todos estos servicios de MT empezaron a cambiar a la traducción automática neuronal, lo cual se ha convertido en la tecnología más común para los consumidores hoy en día. DeepL ha ganado popularidad en los últimos años, un nuevo traductor neuronal que se lanzó en el 2017.
¿Pero cómo funciona la traducción automática en realidad? Ya sabemos todos que se requiere mucho más que solamente un diccionario y algunas reglas gramaticales, pero ¿qué es lo que hacen estas máquinas? ¡Veamos!
Corpus paralelos
Muchos traductores automáticos usan los corpus paralelos, los cuales son bases de datos de textos bilingües de una gama variada de fuentes. Un equipo humano o la inteligencia artificial (IA) selecciona estos textos y los ingresa en el corpus, una biblioteca enorme de traducciones de las cuales la MT puede extraer datos. Estos textos bilingües utilizados en un corpus de MT generalmente originan de una búsqueda específica en todas las páginas que existen en la Internet, es decir, lo más probable es que saquen provecho de trabajos ya realizados por traductores humanos. Resultaría difícil verificar la exactitud de estas traducciones o incluso saber cómo se han seleccionado, pero lo que sí sabemos, es que son el resultado de mucha labor humana.
El corpus utilizado por DeepL se llama Linguee y la empresa afirma que este mismo mejora los corpus tradicionales al usar “bots” de Internet especializados que se denominan “crawlers” que de forma automática buscan traducciones que ya existen en Internet. Estos crawlers también evalúan la calidad de las traducciones que van recolectando, aunque esta empresa alemana no da mayores explicaciones sobre cómo funciona este proceso.
Si utiliza Google para buscar una traducción y escribe la frase “en español” o “en francés”, etc., es probable que Linguee aparezca dentro de las primeras páginas en esta búsqueda. Esta popularidad en las búsquedas de Google le permitió a Linguee generar ingresos de los anuncios en su página web antes del lanzamiento de DeepL.

Traducción automática estadística (SMT por sus siglas en inglés)
El Traductor de Google, posiblemente el servicio de MT más conocido en el mundo, antes usaba la tecnología de traducción automática estadística. Gran parte de sus competidores también la utilizaba, como el Traductor de Microsoft (anteriormente conocido como Bing) y Yandex Translate de una empresa rusa.
Al ingresar un texto fuente, la SMT usa las estadísticas para determinar la traducción más probable en base del corpus. No conoce ni entiende las reglas gramaticales ni los usos más comunes del lenguaje, sino que logra captar la traducción más probable matemáticamente en base de las traducciones en el corpus que sirven como ejemplo.
La gramática, sintaxis y las limitaciones del corpus presentan grandes desafíos para la SMT y solamente puede traducir una frase si ya existe dentro del mismo corpus. Aunque no existe, si el traductor automático no encuentra muchos resultados para alguna palabra en el corpus, es posible que elija otra palabra que determine sea más estadísticamente probable. Además, en general la SMT se basa en las frases, lo cual limita su capacidad de producir frases o textos más extensos. Haga clic en el link de abajo para leer más sobre la SMT:
Traducción automática neuronal (NMT por sus siglas en inglés)
Hoy en día, el Traductor de Google, DeepL y todos sus competidores usan la traducción automática neuronal. Este método también emplea los corpus paralelos, pero deja de lado los modelos estadísticos por las redes neuronales artificiales. Estas redes son sistemas informáticos diseñados para imitar el cerebro humano. Son capaces de reconocer patrones dentro del corpus y producir resultados basados en estos mismos patrones. Este proceso también se conoce como aprendizaje profundo (Deep Learning en inglés) y de ahí viene el nombre de DeepL.
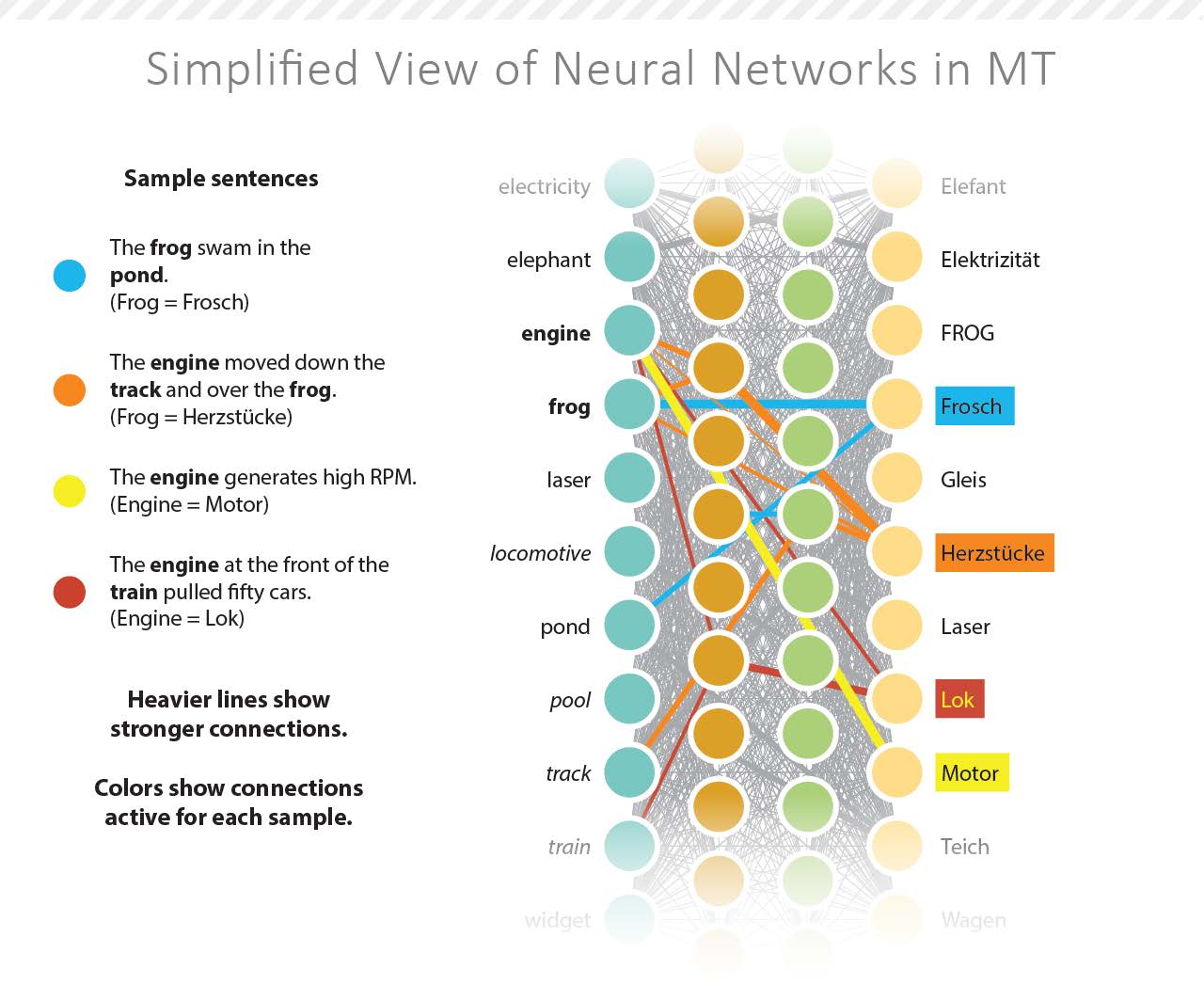
Este aprendizaje profundo puede ser aprendizaje supervisado, no supervisado o semi-supervisado por los programadores humanos. DeepL no ha compartido mucha información sobre el funcionamiento de estas supuestas mejoras. Para aprender más sobre el aprendizaje automático y cómo se relaciona con la traducción, vea el enlace de abajo:
Las traducciones automáticas neuronales son más precisas que las de SMT y parecen ser traducciones más “fluidas”, pero esta fluidez superficial muchas veces enmascara problemas más profundos con la precisión, exactitud y comprensión. Veamos el ejemplo de abajo:

“Only the best will do” es un modismo bastante común en inglés. La traducción de DeepL no presenta ningún error gramatical, pero no tiene sentido en español. Como la mayoría de los usuarios de MT no son bilingües, es posible que no logren detectar este error.
Esta tecnología ha tenido grandes avances, pero que no se engañen: la NMT no produce traducciones absolutamente precisas ni fluidas. Para documentos técnicos importantes o comunicaciones con clientes, es posible que no sea la mejor opción para su negocio. En Southern Cone Translations, estamos felices de ayudarle a explorar todas las opciones para encontrar la que más le convenga. Póngase en contacto con nosotros si tiene cualquier duda o consulta.
¿Será la traducción automática la mejor opción para poder resguardar su imagen profesional? Lea nuestro último blog para conocer más
